How This Benchmark Works
This benchmark evaluates different parameter estimation and curve fitting approaches
using synthetic data with known ground truth values.
Methodology:
-
Test Data Generation: 50
different parameter sets are randomly generated for the wavelet function.
For each parameter set, synthetic data is created with 5% noise added.
- Methods Compared:
- Simple + lmfit:
Uses central values from parameter ranges as starting points
- ZeroGuess + lmfit:
Uses ZeroGuess's neural network to estimate starting parameters
- True + lmfit:
Uses the true parameters as starting points (best case scenario)
Each method is tested with different optimization algorithms (least_squares, dual_annealing)
- Metrics:
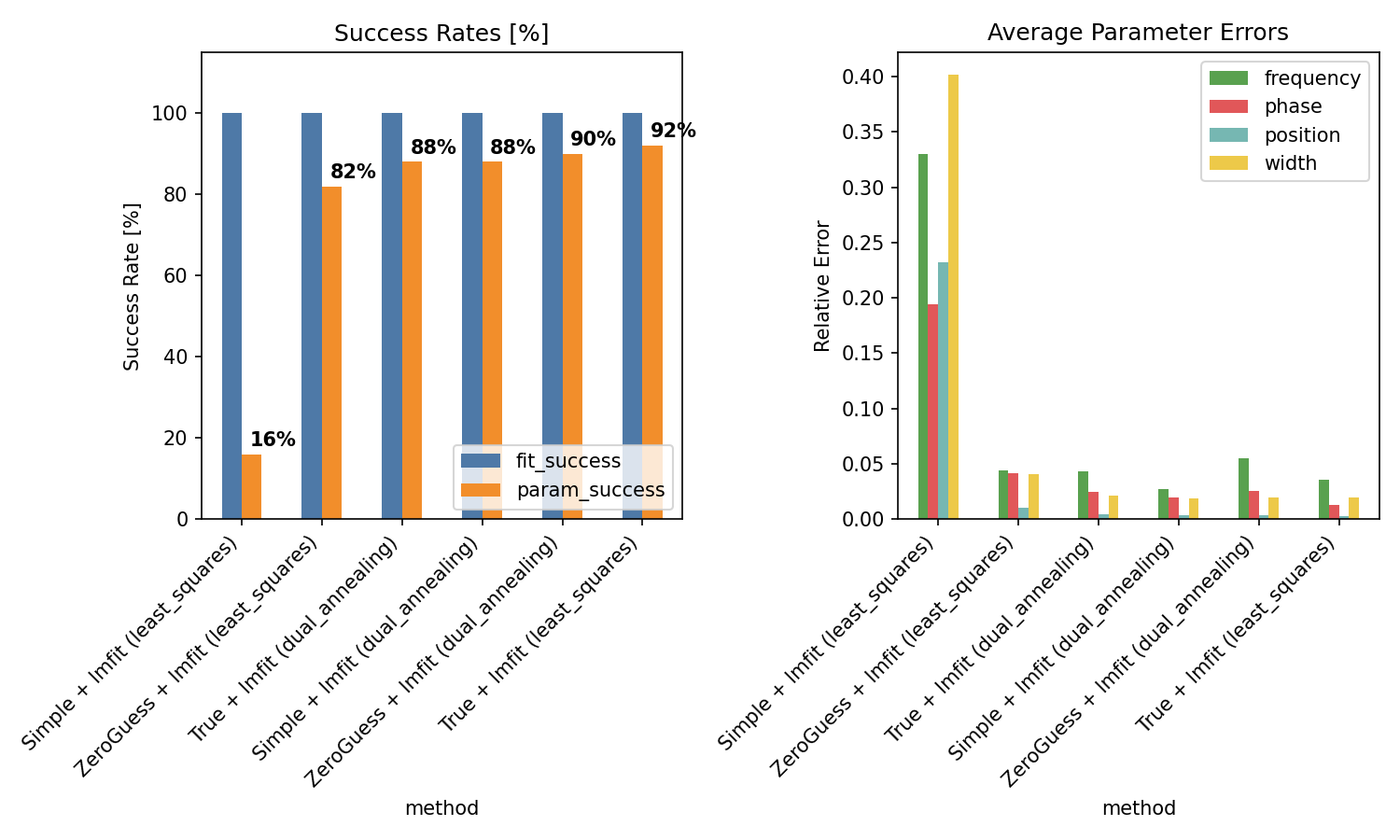
- Fit Success:
Whether the fitting algorithm converged
- Parameter Success:
Whether all recovered parameters are within 10% of true values
- Computation Time:
Time for parameter estimation and fitting
- Function Evaluations:
Number of function calls required
_set_1.png)
_set_2.png)
_set_3.png)
_set_1.png)
_set_2.png)
_set_3.png)
_set_1.png)
_set_2.png)
_set_3.png)
_set_1.png)
_set_2.png)
_set_3.png)
_set_1.png)
_set_2.png)
_set_3.png)
_set_1.png)
_set_2.png)
_set_3.png)